Since this is the 20th anniversary of Matt’s original CRAN submission, I wanted to do some analysis of contributors over time, to emphasize the great community that has been working to improve data.table in recent years. To do that, we first download data on all releases, using code from my previous post about the release history of data.table.
Download Archive web page
We can download the Archive web page for data.table via the code below,
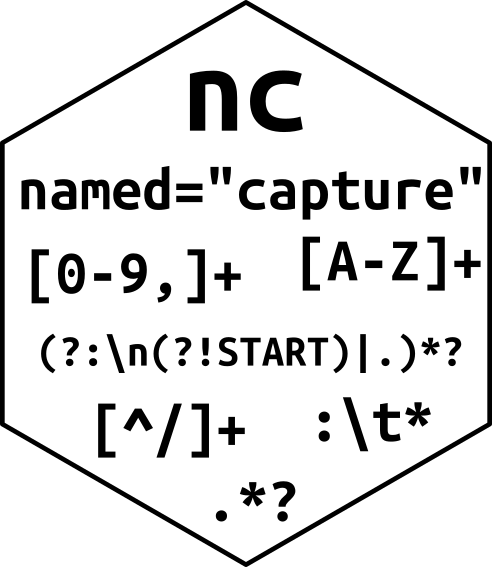
The output above shows that the Archive web page has a regular structure, which we can convert into a data table using the regular expression pattern below.
file=file.pattern which means to apply the previous regex, and put the matching text in the file column,
"</a>" which matches the closing </a> tag
"\\s+" which matches one or more white space characters,
IDate=".*?", as.IDate, which matches zero or more characters (non-greedy, as few as possible), then use as.IDate to convert the text to efficient integer date, saved in the IDate column,
"\\s" means to match one white space character.
The end result is a table with one row for each matched package version, and one column for each of the named arguments:
Above the table shows all matches, in the same order as the original Archive web page. Below we key the table by date, which sorts the data in place (without allocating any new memory), and enables fast joins.
The code above sets the key of the grid, which sorts and enables fast joins. No variables were specified to setkey(); the default is to use all columns, in this case just one. Note that setkey() sets the key by reference, then returns the table.
Next, we do a rolling join to find which releases are nearest to each date in the grid.
The output above shows one row per release we will analyze. For each release, we download the package sources from the Archive, and extract the Author field of DESCRIPTION.
version release Author no.newlines
<char> <IDat> <char> <char>
1: 1.0 2006-04-14 Matt Dowle Matt Dowle
2: 1.6 2011-04-24 Matthew Dowle with many contri... Matthew Dowle with many contri...
3: 1.9.6 2015-09-19 M Dowle, A Srinivasan, T Short... M Dowle, A Srinivasan, T Short...
4: 1.10.4 2017-02-01 Matt Dowle [aut, cre],\nArun Sri... Matt Dowle [aut, cre], Arun Sr...
5: 1.11.0 2018-05-01 Matt Dowle [aut, cre],\nArun Sri... Matt Dowle [aut, cre], Arun Sr...
6: 1.12.2 2019-04-07 Matt Dowle [aut, cre],\nArun Sri... Matt Dowle [aut, cre], Arun Sr...
7: 1.13.0 2020-07-24 Matt Dowle [aut, cre],\nArun Sri... Matt Dowle [aut, cre], Arun Sr...
8: 1.14.0 2021-02-21 Matt Dowle [aut, cre],\nArun Sri... Matt Dowle [aut, cre], Arun Sr...
9: 1.14.4 2022-10-17 Matt Dowle [aut, cre],\nArun Sri... Matt Dowle [aut, cre], Arun Sr...
10: 1.14.8 2023-02-17 Matt Dowle [aut, cre],\nArun Sri... Matt Dowle [aut, cre], Arun Sr...
11: 1.15.4 2024-03-30 Tyson Barrett [aut, cre],\nMatt ... Tyson Barrett [aut, cre], Matt...
12: 1.17.2 2025-05-12 Tyson Barrett [aut, cre] (ORCI... Tyson Barrett [aut, cre] (ORCI...
13: 1.18.0 2025-12-24 Tyson Barrett [aut, cre] (ORCI... Tyson Barrett [aut, cre] (ORCI...
The output above has a new column of comma-separated authors per release (with no newlines). We would like to convert these data to a table with one year per author. A simple approach would be
[[1]]
[1] "Matt Dowle"
[[2]]
[1] "Matthew Dowle with many contributions from Tom Short. See SVN logs on R-Forge."
[[3]]
[1] "M Dowle" "A Srinivasan"
[3] "T Short" "S Lianoglou with contributions from R Saporta"
[5] "E Antonyan"
[[4]]
[1] "Matt Dowle [aut" "cre]" "Arun Srinivasan [aut]" "Jan Gorecki [ctb]"
[5] "Tom Short [ctb]" "Steve Lianoglou [ctb]"
[[5]]
[1] "Matt Dowle [aut" "cre]" "Arun Srinivasan [aut]" "Jan Gorecki [ctb]"
[5] "Michael Chirico [ctb]" "Pasha Stetsenko [ctb]"
[[6]]
[1] "Matt Dowle [aut" "cre]" "Arun Srinivasan [aut]" "Jan Gorecki [ctb]"
[5] "Michael Chirico [ctb]" "Pasha Stetsenko [ctb]"
It is clear that the result above does not quite work (Matt’s aut, cre role contains a comma so is broken into two entries). Instead we can use
author.pattern <-list(name=".+?", nc::quantifier(" \\[",roles=".+?","\\]","?"), nc::quantifier(" \\(", paren=".+?","\\)","?"),## each author ends with one of these (\z means end of string). nc::alternatives(" with (?:many )?contributions from ", ", ", "\\z"))(author.dt <- desc.dt[, nc::capture_all_str( no.newlines, author.pattern), by=.(version, release)])
version release name roles paren
<char> <IDat> <char> <char> <char>
1: 1.0 2006-04-14 Matt Dowle
2: 1.6 2011-04-24 Matthew Dowle
3: 1.6 2011-04-24 Tom Short. See SVN logs on R-...
4: 1.9.6 2015-09-19 M Dowle
5: 1.9.6 2015-09-19 A Srinivasan
---
550: 1.18.0 2025-12-24 Reino Bruner ctb
551: 1.18.0 2025-12-24 @badasahog ctb GitHub user
552: 1.18.0 2025-12-24 Vinit Thakur ctb
553: 1.18.0 2025-12-24 Mukul Kumar ctb
554: 1.18.0 2025-12-24 Ildikó Czeller ctb
The table above has one row for each time a person appears in the Author field of one of the releases. We will analyze the roles.
author.dt[roles==""]
version release name roles paren
<char> <IDat> <char> <char> <char>
1: 1.0 2006-04-14 Matt Dowle
2: 1.6 2011-04-24 Matthew Dowle
3: 1.6 2011-04-24 Tom Short. See SVN logs on R-...
4: 1.9.6 2015-09-19 M Dowle
5: 1.9.6 2015-09-19 A Srinivasan
6: 1.9.6 2015-09-19 T Short
7: 1.9.6 2015-09-19 S Lianoglou
8: 1.9.6 2015-09-19 R Saporta
9: 1.9.6 2015-09-19 E Antonyan
We see some old entries above with missing roles, which we fill in below.
Role
roles ctb aut <NA>
5 4 0
aut 0 26 0
aut, cre 0 10 0
ctb 509 0 0
<NA> 0 0 0
Above we use fcase() to create a new Role column, with factor levels in a non-default order (to control legend entry display order below). Then we chain square brackets to display a table which shows how roles are mapped to Role. The counts look reasonable, so the next step is to count how many people with each role in each release:
release version Role people
<IDat> <char> <fctr> <int>
1: 2006-04-14 1.0 aut 1
2: 2011-04-24 1.6 aut 1
3: 2011-04-24 1.6 ctb 1
4: 2015-09-19 1.9.6 aut 2
5: 2015-09-19 1.9.6 ctb 4
---
21: 2024-03-30 1.15.4 ctb 65
22: 2025-05-12 1.17.2 aut 8
23: 2025-05-12 1.17.2 ctb 81
24: 2025-12-24 1.18.0 aut 8
25: 2025-12-24 1.18.0 ctb 86
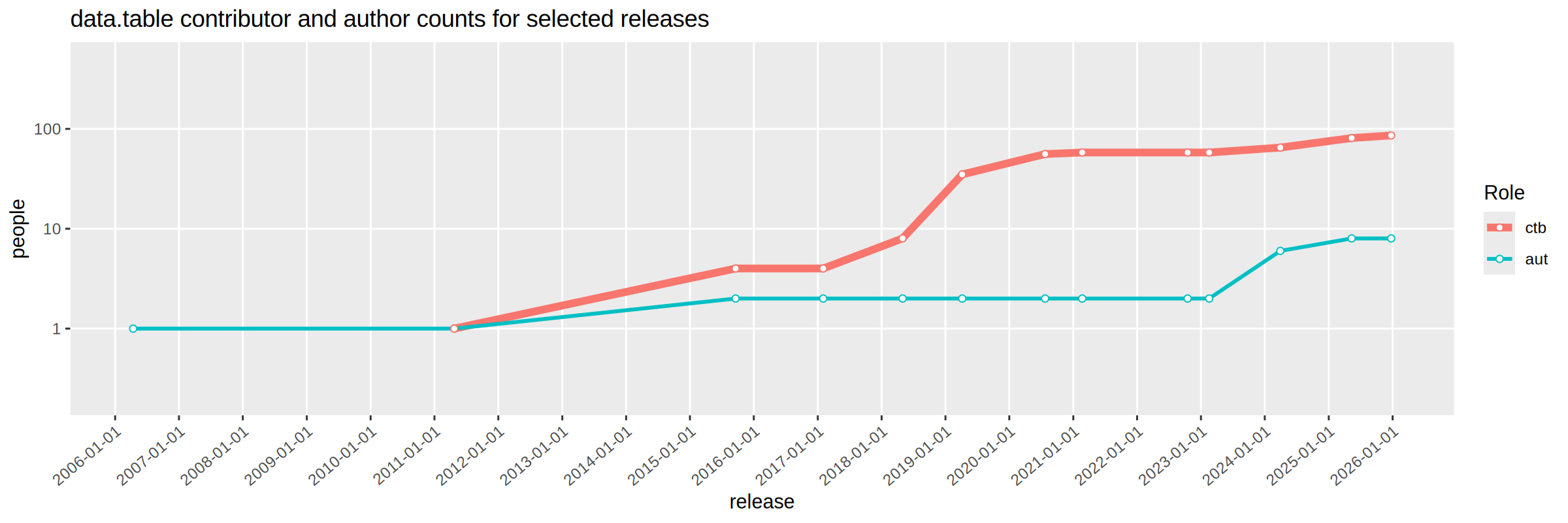
How has this evolved in the past ten years?
library(ggplot2)gg <-ggplot(count.dt, aes( release, people, color=Role))+ggtitle("data.table contributor and author counts for selected releases")+theme(panel.grid.minor=element_blank(),axis.text.x=element_text(hjust=1, angle=40))+geom_line(aes(linewidth=Role))+geom_point(shape=21, fill="white")+scale_x_date(breaks="year")+scale_linewidth_manual(values=linewidth.values)+scale_y_log10(limits=c(0.2, 500))gg
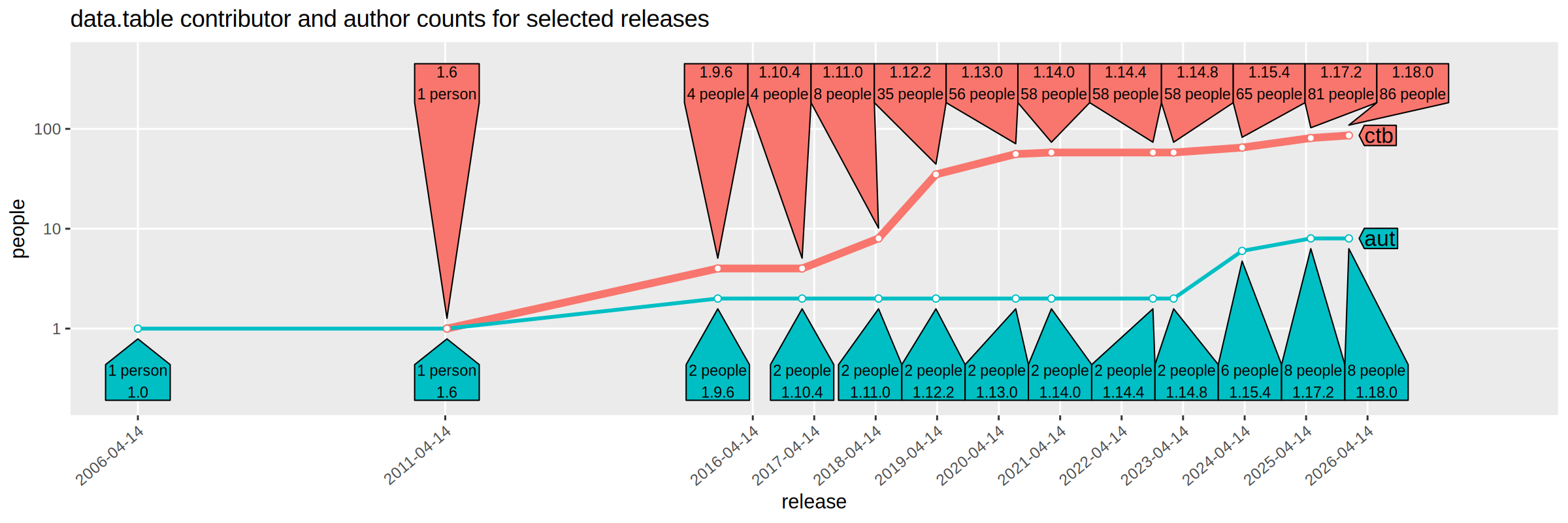
Above we see a time series showing the increasing authors and contributors over time. To emphasize the values at each release, we add direct labels below:
pp <-function(num)sprintf("%d %s", num, ifelse(num==1, "person", "people"))## To define upper limit of X scale, we use prop.## prop=0 means no extra space.## prop=0.1 means 10% more space, etc.prop <-0.1space.cm <-0.2# space between polygon point and data point.poly.method <-function(position, direction)substitute(list( directlabels::dl.trans(cex=0.7, # text size of direct labels.y=y+YSPACE), directlabels::polygon.method( POSITION, offset.cm=0.5)), #space between polygon point and text.list(YSPACE=direction*space.cm, POSITION=position))directlabels::direct.label( gg, list(directlabels::dl.trans(x=x+space.cm), "right.polygons"))+scale_x_date(breaks=grid.dt$grid.IDate,limits=grid.dt[, { i <-as.integer(grid.IDate)as.IDate(c(min(i), (1+prop)*max(i)-prop*min(i))) }])+ directlabels::geom_dl(aes(label=sprintf("%s\n%s", version, pp(people))),data=count.dt[Role=="ctb"],method=poly.method("top", 1))+ directlabels::geom_dl(aes(label=sprintf("%s\n%s", pp(people), version)),data=count.dt[Role=="aut"],method=poly.method("bottom", -1))
Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
ℹ Please use tidy evaluation idioms with `aes()`.
ℹ See also `vignette("ggplot2-in-packages")` for more information.
ℹ The deprecated feature was likely used in the directlabels package.
Please report the issue at <https://github.com/tdhock/directlabels/issues>.
Warning in geom_dl(mapping = a2, method = method, stat = L$stat, debug = debug, : Ignoring unknown
aesthetics: linewidth
Scale for x is already present.
Adding another scale for x, which will replace the existing scale.
The figure above shows that the number of authors and contributors has greatly expanded in the second decade of data.table. I’m looking forward to the third decade!
Update of the previous blog
The rest of this post is copied from my previous post, with an update based on recent data.
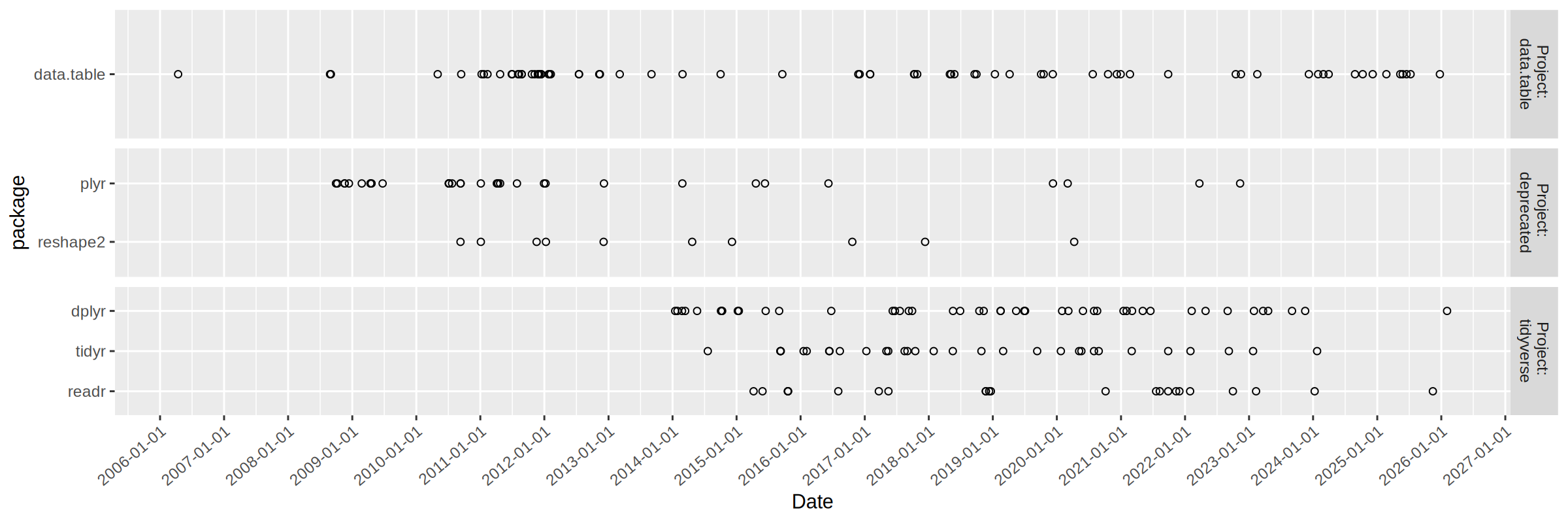
Analyze several packages for comparison
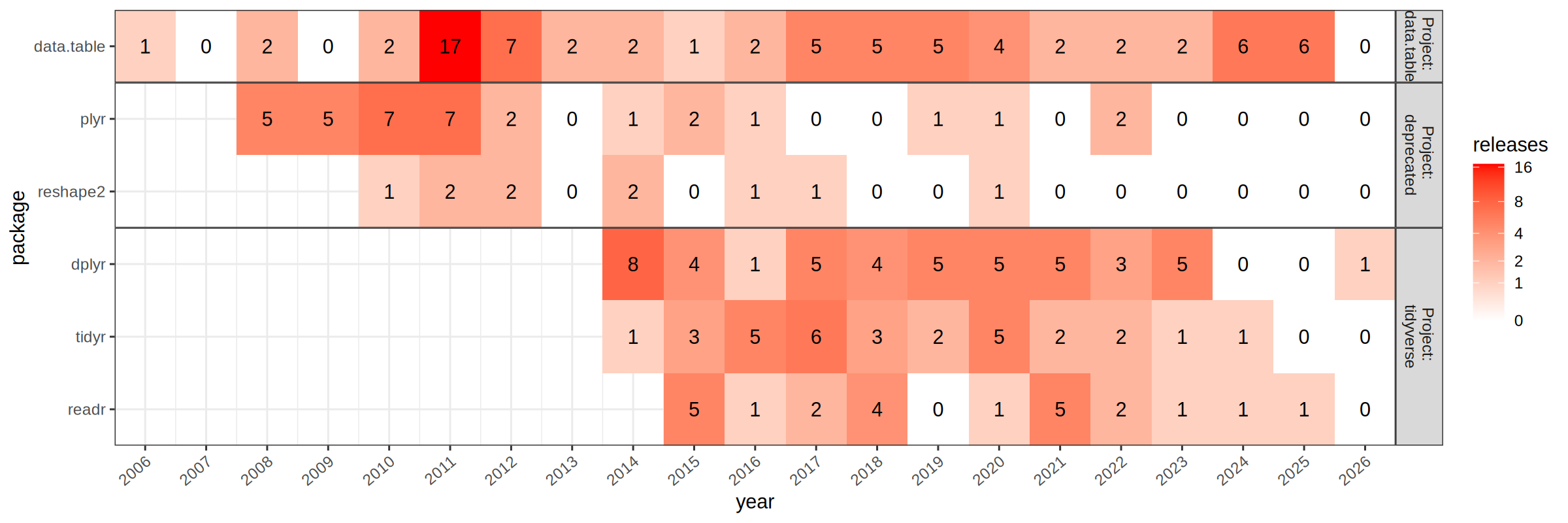
The code below defines a set of four packages for which we would like to analyze the release history (tidyverse packages for comparison).
The result above is a data table with one row for each package version. Note that the code set by to all column names, so that the code is run for each row/package.
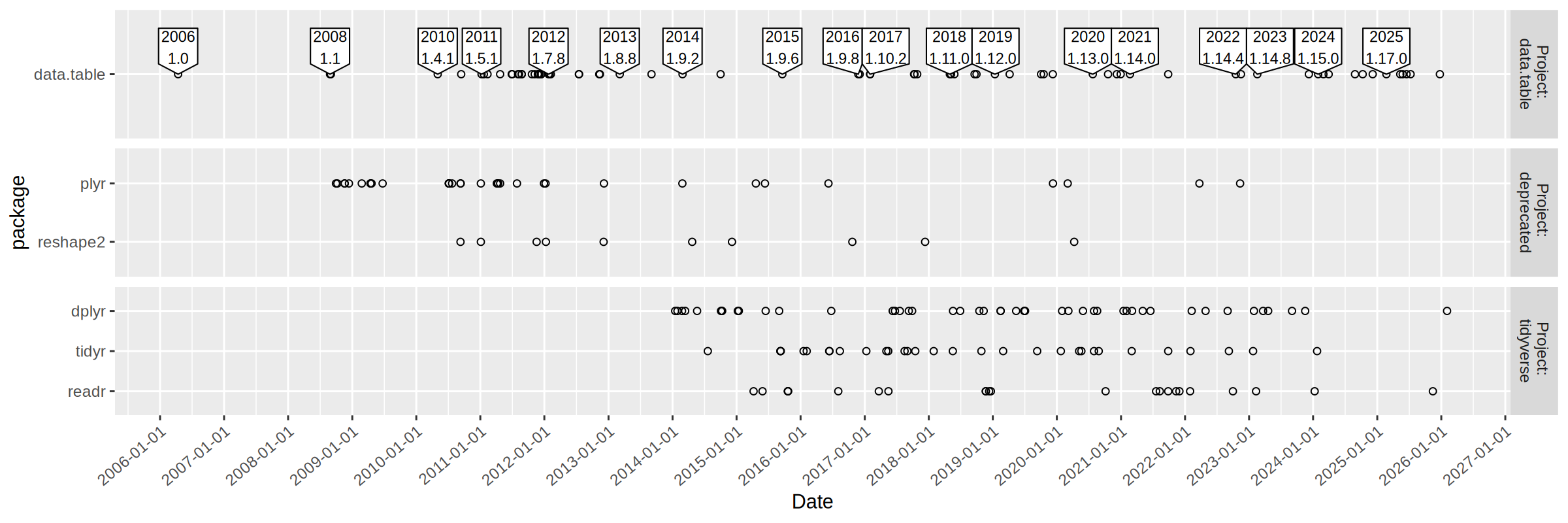
Another way to do it would be to compute the number of releases in each year since the release of the package. To do that we first compute, for each package, a set of years for which we want to count releases.
Note that on=.NATURAL above means to join on the common columns between the two tables, and by=.EACHI means to compute a summary for each value specified in i (the first argument in the square bracket). We can plot these data as a heat map via
The table above show similar numbers for the two methods of computing the number of releases per year.
Conclusion
We have shown how to download CRAN package release data, how to parse the web pages using the nc package and regular expressions, how to summarize/analyze using data.table, and how to visualize using ggplot2.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}